XML, HTML, XHTML は構造化言語です。構造化プログラミングとはちょっと(完全に)違うのですが、同じ流れにあるものと考えられます。構造化言語とは、文書の意味を構造として明示する言語のことです。全体を要素の集合として捉えることだともいえます。更に云えば、全体を木構造で表すことです。そのノード(節)が要素であり、要素の内容は下層ノードです。
だんだん難しくなってしまいました。具体例を見たほうが簡単でしょう。
<body>
<h1>構造化言語</h1>
<h2>木構造</h2>
<p>木構造とは、各要素が、各々ただ一つの親要素を持つ場合を指します。
例外は、最大レベルの要素であり、親要素を持ちません。この要素のことは
特に、ルート要素と呼びます。</p>
<h2>構造</h2>
<p>プログラミングでは、構造化プログラミングと呼ばれるものがあります。
これは、順次実行、繰り返し、条件分岐の三つだけの制御構造を用いてコー
ディングすることです。</p>
<p>このことによって、各ブロックを要素とする木構造を定義すれば、これ
を順次探索する順番で処理が実行されていきます。</p>
<p>これと同様に、 XML でも各要素をノードとして木構造を定義できます。
文書の意味は、この木構造を順次探索する順番で理解されますし、各種の処理
エンジンの処理対象にもなり得ます。</p>
</body>
上の例では、本文 body の中に、最大見出し h1、見出しレベル2 h2、段落 p の三つの要素が入っています。これら三つの要素は、 body 要素に対して階層が横並びの子要素です。XML, XHTML としては正しいのですが、文書構造と言う点では十分構造化されていません。と言うのは、意味的には h2 は h1 より下層の要素であるはずですし、 p は更に下層のはずです。というわけで、文書の意味を十分反映させて見ましょう:
<body>
<div class="chapter">
<h1>構造化言語</h1>
<div class="section">
<h2>木構造</h2>
<div class="paragraph">
<p>木構造とは、各要素が、各々ただ一つの親要素を持つ場合を指します。
例外は、最大レベルの要素であり、親要素を持ちません。この要素のことは
特に、ルート要素と呼びます。</p>
</div> <!--paragraph end-->
</div> <!--section end-->
<div class="section">
<h2>構造</h2>
<div class="paragraph">
<p>プログラミングでは、構造化プログラミングと呼ばれるものがあります。
これは、順次実行、繰り返し、条件分岐の三つだけの制御構造を用いてコー
ディングすることです。</p>
<p>このことによって、各ブロックを要素とする木構造を定義すれば、これ
を順次探索する順番で処理が実行されていきます。</p>
<p>これと同様に、 XML でも各要素をノードとして木構造を定義できます。
文書の意味は、この木構造を順次探索する順番で理解されますし、各種の
処理エンジンの処理対象にもなり得ます。</p>
</div> <!--paragraph end-->
</div> <!--section end-->
</div> <!--chapter end-->
</body>
冗長になってしまいましたが、これで文書の構造がマークアップで反映されています。文書構造を反映する操作、例えば、「 section を隠して、 chapter だけ表示する」、「 section の h2 だけ表示して paragraph を隠す」などの処理が行えます。これが文書の構造化です。
木構造という観点から見てみましょう。
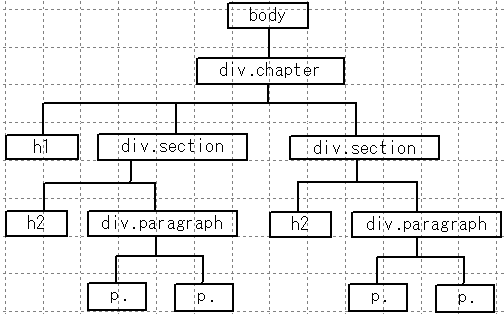
図: XHTML 文書の木構造
最大要素=ルート要素は、 body 要素です。 body 要素の子要素は div.chapter 要素です。 div.chapter 要素はその見出し h1 と内容 div.section 要素です。 div.section 要素の子要素はその見出し h2 と内容 div.paragraph 要素です。 div.paragraph 要素の内容は段落である p 要素です。
勿論、他の構造化が適切な場合もあるでしょう。例えば、上に挙げた例では、 div.chapter を用いた構造化は冗長だと思います。なぜなら、 div.chapter は階層を一段階増やしているだけで、なんら構造の簡略化=グループ化に寄与していないからです。一方、 h1 要素が複数存在するような場合(チャプターが複数存在するような場合)は、 body 要素を構成する構造が、複数の div.chapter として捉えられるので、有意義な構造化だといえます。また、チャプター以外の構造として address 要素が現れる場合にも有意義な構造化でしょう。
つまり、目的に応じてどの水準まで構造化すれば良いのかは異なってきます。 XML ではツールによる自動処理が念頭におかれているので、記述者や閲覧者が暗黙に了解できることでも、マークアップで明示する必要があるのです。機械に暗黙の了解も解析できるようにするのは無理があるか、できてもツールの設計が複雑になるだけです。
XML, XHTML では、文書の木構造の末端のノード=リーフは文字データ (PCDATA) になり、一番上のノード=ルートは html 要素になります。構造化の水準とは、この両端の間を何階層に分けるかと言うことになります。
